This introduction provides an overview of Vitis HLS pragmas, their purpose, and how to effectively use them to optimize high-level synthesis designs.
FPGA HLS: An Introduction to Vitis HLS Pragmas
在使用 Vitis HLS 进行高层次综合 (HLS) 设计时, 除了标准的 C++ 代码外, 更重要的是使用 Vitis HLS 提供的编译指令, 也就是 pragma HLS 来指导编译器进行更多优化. 通常情况下 Vitis HLS 编译器几乎不会做任何优化, 因此生成出来的硬件电路往往性能很低. 使用编译指令主要的目标就是最大化并行, 最大化吞吐, 最小化延迟, 最小化资源使用等. 本文将介绍 Vitis HLS 中常用的编译指令及其使用方法.
什么是 Pragma
Pragma 是编译器指令的缩写, 用于向编译器提供额外的信息或指示. Pragma 不仅限于 HLS, 很多领域的编译器都需要依赖 Pragma 来像编译器提供额外的优化信息, 例如 OpenMP 中的 #pragma omp parallel , CUDA 中的 #pragma unroll . 它们的一大特点就是高度依赖编译器的实现, 每个编译器出于领域的不同需求, 都会定义自己的一套 Pragma 指令集. 在 Vitis HLS 中, Pragma 以 #pragma HLS 开头, 后面跟随具体的指令内容. 常见的 Pragma 包括以下这些, 接下来将逐一介绍.
#pragma HLS interface: 定义模块的接口类型, 常见的有 AXI4, AXI4-Lite, AXI-Stream 等.#pragma HLS array_partition: 用于将数组分割成多个独立的存储块, 以提高并行访问能力.#pragma HLS pipeline: 用于将循环或函数调用进行流水线化, 最小化启动间隔, 提高吞吐量.#pragma HLS unroll: 用于将循环展开, 增加并行度, 减少循环控制开销.#pragma HLS dataflow: 用于启用数据流优化, 允许不同函数或循环之间并行执行.#pragma HLS bind_storage: 用来指定数组或变量的存储类型, 例如 BRAM, LUTRAM, URAM 等. 这个选项在旧版被称为#pragma HLS resource.#pragma HLS bind_op: 用于指定算术运算的实现方式, 例如使用 DSP 还是 LUT 还是 DSP/LUT 混合实现某种运算.
为了更清楚地展示这些 Pragma 的作用, 本文将通过对比综合报告/上板验证/调度时序图等方式展示使用前后的差异. 使用的开发版是 Kria SOM KV260, 核心是一块 ZynqMP, 使用 2025.2 版本的 Vitis HLS 工具链进行综合和实现.
我们主要将围绕一个最简单的向量加法器展开, 这是一个并行计算的经典例子. 下面是未做任何优化的, 符合常规软件思维写法的例子:
void vec_add(const int *a, const int *b, int *c, int size) {
for (int i = 0; i < size; i++) {
c[i] = a[i] + b[i];
}
}#pragma HLS interface
在硬件上, 一个模块必须有清晰的接口定义, 用来和外部进行数据交互. 数据从用途上可以分成两类: 控制信号和数据信号, 很显然前者并不需要太高的传输带宽和频率, 而后者的传输速度和延迟通常决定了整个模块的性能. 从交互对象又可以分成两类: PS/PL 交互和 PL/PL 交互. PS/PL 交互通常使用 AXI4/AXI4-Lite/AXI-Stream 等总线协议, 而 PL/PL 交互可以使用 FIFO/BRAM, 甚至就是个普通的端口. 为了给编译器提供这些信息 (用来表明我们的设计意图), 我们需要使用 #pragma HLS interface 来定义接口类型.
那么如何选择合适的接口类型呢? 这里有几个原则:
- 控制类信号使用 AXI4-Lite 接口, 它一般连接到 PS 端的 LPD 总线上, 频率低, 位宽小, 资源占用低.
- 和 DDR 直接交互的数据信号使用 AXI4 接口, 它一般连接到 PS 端的 HP 总线上 (如果 DDR 控制器集成在 PS 端, 例如 Zynq 系列). AXI4 接口支持高带宽传输, 适合大数据量的读写操作.
- PS 和 PL 之间传输流式数据的时候, 使用 AXI-Stream 接口, 它同样有很高的带宽, 并且由于流式传输的特性, 并且它相比 AXI4 更精简, 因此资源占用更低, 并且能够实现更低的延迟.
- 怎么样才满足流式传输? 首先一段数据流中的数据, 一旦被读取过了, 它就会从流中被移除, 这是所谓的 “阅后即焚” 特性. 其次, 为了防止严重的背压影响效率, 生产者和消费者之间处理数据的速率应该大致相当, 否则就会出现生产者频繁等待消费者读取数据, 或者消费者频繁等待生产者写入数据的情况.
- PL 上的不同模块之间传输非流式数据的时候 (比如双缓冲), 使用 BRAM 端口.
- PL 上的不同模块之间传输流式数据的时候, 使用 FIFO 端口.
大多数情况下以上的原则都能满足需求, 小部分情况可能需要参考 Vitis 手册进行调整.
在我们的例子中, 为了简单起见, 我们假设 PL 上的向量加法器直接从 DDR 读取输入向量, 计算后将结果写回 DDR. 为此我们应该将输入和输出的数据端口都定义为 AXI4 接口. 而 size 参数是用来控制向量的长度的, 它数据量极小, 属于控制信号, 因此我们将它定义为 AXI4-Lite 接口.
void vec_add(const int *a, const int *b, int *c, int size) {
#pragma HLS interface m_axi port=a offset=slave bundle=gmem0
#pragma HLS interface m_axi port=b offset=slave bundle=gmem1
#pragma HLS interface m_axi port=c offset=slave bundle=gmem2
#pragma HLS interface s_axilite port=a bundle=control
#pragma HLS interface s_axilite port=b bundle=control
#pragma HLS interface s_axilite port=c bundle=control
#pragma HLS interface s_axilite port=size bundle=control
#pragma HLS interface s_axilite port=return bundle=control
for (int i = 0; i < size; i++) {
c[i] = a[i] + b[i];
}
}#pragma HLS interface 支持很多参数, 挑一些常用的来介绍:
port=: 指定接口所作用的端口名称.mode=: 指定接口的模式, 常见的有m_axi,s_axilite,axis,ap_fifo,bram等. 这个mode=前缀可以省略不写, 如上所示.offset=: 仅对 AXI4/AXI4-Lite 接口有效, 并且 AXI4-Lite 接口通常无需手动配置. 对于 AXI4 接口, 通常使用offset=slave, 表示地址偏移由外部主机 (PS) 提供.- 这个地址偏移是什么意思呢? 要访问一块内存, 必须知道它的绝对地址. 但在硬件设计中, 显然你无法预先知道这块内存的绝对地址, 你只能在函数体内用相对偏移量来访问内存, 例如上面的
a[i],b[i],c[i]. 那么这个相对偏移量如何转换成绝对地址呢? 这就需要一个基地址. 这个基地址实际上也是一个控制信号, 通过 AXI4-Lite 连接到 PS 上. 模块工作的时候, PS 端的驱动程序将这个基地址写入到模块的控制寄存器中, 模块再根据这个基地址加上相对偏移量计算出绝对地址, 从而访问内存.
- 这个地址偏移是什么意思呢? 要访问一块内存, 必须知道它的绝对地址. 但在硬件设计中, 显然你无法预先知道这块内存的绝对地址, 你只能在函数体内用相对偏移量来访问内存, 例如上面的
bundle=: 用来将端口连接到总线上. 后面跟总线的名称. 绑定到相同bundle的端口会被连接到同一条总线上.- 这有什么影响? 我们都知道在同一条总线上不同的端口不能同时发起传输请求, 只能按先后顺序发起请求, 否则会导致数据冲突. 这会影响数据传输的性能. 那两个端口要怎么配置才能同时发起传输请求呢? 那就将它们连接到不同的总线上.
对于一个模块的控制信号, 将它们全部绑在一个 bundle 中是一个不错的选择 (在 Vitis Flow 中是必须的), 因为控制信号不需要考虑性能的问题, 打包在一个 bundle 里面节省资源, 也方便管理.
为了直观展示 #pragma HLS interface 的作用, 我们综合上面的代码, 并生成综合报告. 下面是综合报告中的接口定义部分:
| Interface | Read/Write | Data Width (SW->HW) | Address Width | Latency | Offset | Register | Max Widen Bitwidth | Max Read Burst Length | Max Write Burst Length | Num Read Outstanding | Num Write Outstanding | Resource Estimate |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
m_axi_gmem0 | READ_ONLY | 32 -> 32 | 64 | 64 | slave | 0 | 512 | 16 | 16 | 16 | 16 | BRAM=2 |
m_axi_gmem1 | READ_ONLY | 32 -> 32 | 64 | 64 | slave | 0 | 512 | 16 | 16 | 16 | 16 | BRAM=2 |
m_axi_gmem2 | WRITE_ONLY | 32 -> 32 | 64 | 64 | slave | 0 | 512 | 16 | 16 | 16 | 16 |
| Interface | Data Width | Address Width | Offset | Register |
|---|---|---|---|---|
s_axi_control | 32 | 6 | 16 | 0 |
| Interface | Register | Offset | Width | Access | Description | Bit Fields |
|---|---|---|---|---|---|---|
s_axi_control | CTRL | 0x00 | 32 | RW | Control signals | 0=AP_START 1=AP_DONE 2=AP_IDLE 3=AP_READY 4=AP_CONTINUE 7=AUTO_RESTART 9=INTERRUPT |
s_axi_control | GIER | 0x04 | 32 | RW | Global Interrupt Enable Register | 0=Enable |
s_axi_control | IP_IER | 0x08 | 32 | RW | IP Interrupt Enable Register | 0=CHAN0_INT_EN 1=CHAN1_INT_EN |
s_axi_control | IP_ISR | 0x0c | 32 | RW | IP Interrupt Status Register | 0=CHAN0_INT_ST 1=CHAN1_INT_ST |
s_axi_control | a_1 | 0x10 | 32 | W | Data signal of a | |
s_axi_control | a_2 | 0x14 | 32 | W | Data signal of a | |
s_axi_control | b_1 | 0x1c | 32 | W | Data signal of b | |
s_axi_control | b_2 | 0x20 | 32 | W | Data signal of b | |
s_axi_control | c_1 | 0x28 | 32 | W | Data signal of c | |
s_axi_control | c_2 | 0x2c | 32 | W | Data signal of c | |
s_axi_control | size | 0x34 | 32 | W | Data signal of size |
在编译之后, 综合报告中显示了模块的接口定义. 可以看到, 输入 a , b 和输出 c 都被综合成 AXI4 接口, 并且每个接口单独对应一条总线接口 ( bundle ), 这样这个模块的输入输出就可以接到不同的上游/下游模块的不同总线上, 从而实现更高的并行传输能力.
接着看控制接口部分, 可以看到所有的控制信号都被打包在一个 AXI4-Lite 总线接口上 ( s_axi_control ), 这符合我们的预期设计. 编译器还提供了控制寄存器映射表, 里面显示了每个控制信号的作用, 以及它们在这条总线上的地址偏移量. 例如 size 信号对应的寄存器地址偏移量是 0x34 , 这意味着如果我们想改变向量的长度, 就需要在 PS 上将向量长度写入这个总线的基地址加上 0x34 的位置.
可以注意到控制信号里面还有 6 条 "Data Signal", 它们用来存放输入输出向量的基地址.
- 我们前面提到过, 通过 M_AXI 接口访问内存的时候, 在设计模块的时候是不可能预先知道要访问的内存的绝对地址的, 只能通过给定一个指针, 然后通过相对偏移量来访问内存中的数据. 那么实际工作的时候, 这个指针的值 (也就是要访问的内存的绝对地址) 从哪里来呢? 这就需要控制总线告诉模块, 也就是 "Data Signal" 的作用.
- DDR 基本都是 64 位地址宽度, 但 AXI-Lite 总线通常只有 32 位宽度, 因此我们需要两个寄存器来存放一个 64 位的地址. 例如
a信号, 它被分成了a_1和a_2两个寄存器, 分别存放地址的低 32 位和高 32 位. 在 PS 端的驱动程序中, 我们需要将输入向量a的绝对地址拆成两部分, 分别写入到这两个寄存器中.
一段简单的驱动程序代码如下所示, 使用 XRT 运行时, 可能帮助理解上述内容:
// 加载 xclbin 文件并获取 uuid
auto device = xrt::device(0);
auto uuid = device.load_xclbin("vec_add.xclbin");
// 获取硬件设计句柄, 这里应该使用顶层模块的名称
auto top = xrt::kernel(device, uuid, "vec_add:{vec_add_0}");
// 获取运行实例句柄
auto run = xrt::run(top);
// 初始化输入数据
std::vector<int> a(1024), b(1024), c(1024);
std::memset(a.data(), 1, sizeof(int) * 1024);
std::memset(b.data(), 2, sizeof(int) * 1024);
// 分配设备内存并拷贝输入数据
auto bo_a = xrt::bo(device, a.size() * sizeof(int), top.group_id(0));
auto bo_b = xrt::bo(device, b.size() * sizeof(int), top.group_id(1));
auto bo_c = xrt::bo(device, c.size() * sizeof(int), top.group_id(2));
bo_a.sync(XCL_BO_SYNC_BO_TO_DEVICE, a.size() * sizeof(int), /* offset */0);
bo_b.sync(XCL_BO_SYNC_BO_TO_DEVICE, b.size() * sizeof(int), /* offset */0);
// 设置加速核参数
// 对于 64 位地址, 我们并不需要手动取高低 32 位, xrt 会自动处理
run.set_arg(0, bo_a); // 将 a 的基地址传入加速核
run.set_arg(1, bo_b); // 将 b 的基地址传入加速核
run.set_arg(2, bo_c); // 将 c 的基地址传入加速核
run.set_arg(3, 1024); // size
// 启动加速核
run.start();
run.wait();
// 读取结果数据
bo_c.sync(XCL_BO_SYNC_BO_FROM_DEVICE, c.size() * sizeof(int), /* offset */0);
// ... 结果验证#pragma HLS pipeline
在硬件设计中, 流水线是一种常见的优化技术. 通常给定一个循环, 流水线处理运行在上一次循环迭代还没有完全结束的时候, 就可以开始下一个循环迭代的处理. 这样做的好处是硬件可以尽可能快地接受新的输入, 从而提高整体的吞吐. 先看流水化带来的调度时序图变化:
其中 ld 表示加载, cmp 表示计算, st 表示写回.
假设一条加法 c[i] = a[i] + b[i];, 其中加载 a[i] 和 b[i] 可以同时进行, 总共需要 1 个周期; 加法操作需要 1 个周期, 写回结果 c[i] 需要 1 个周期; 即完成一次完整的迭代需要 3 个周期. 在未流水化的情况下, 如第一幅调度图所示, 每次迭代必须等到前一次迭代完全结束后才能开始下一次迭代, 因此每次迭代的启动间隔 (Initiation Interval, II) 是 3 个周期 (等于一次迭代的总周期数). 而在流水化的情况下, 如第二幅调度图所示, 下一次迭代的加载操作可以在前一次迭代的加载操作完成之后立刻开始, 因此每次迭代的启动间隔 (II) 降低到了 1 个周期. 显然, 总的执行周期数大大减少了.
为了启用流水线优化, 我们只需要在循环前添加一行 #pragma HLS pipeline 即可:
void vec_add(const int *a, const int *b, int *c, int size) {
// ... 省略接口定义部分 ...
for (int i = 0; i < size; i++) {
#pragma HLS pipeline II=1
c[i] = a[i] + b[i];
}
}如调度图所示, 在这种理想的情况下, 启动间隔 (II) 可以达到 1 个周期 (II 不可能小于 1), 这是一个非常好的流水化结果. 但很多时候启动间隔是不可能到达 1 的, 通常是因为数据依赖或者资源冲突. 例如, 如果将顶层端口 a, b 绑定到同一条 AXI4 总线上, c 绑在另一条总线上. 同一总线上不同端口的读请求不能同时发起, 因此加载 a[i] 和 b[i] 只能串行进行, 下一次迭代的加载操作必须等到当次迭代的两次加载操作都完成之后才能开始, 这样启动间隔 (II) 就变成了 2 个周期. 调度图如下:
这种原因属于资源冲突, 通过增加总线数量或者增加总线带宽可以解决这个问题. 另外一种常见的原因是数据依赖, 例如下面的代码:
void reduce_add(const int *a, const int *b, int c, int size) {
#pragma HLS interface m_axi port=a offset=slave bundle=gmem0
#pragma HLS interface m_axi port=b offset=slave bundle=gmem1
for (int i = 0; i < size; i++) {
#pragma HLS pipeline II=???
c += a[i] + b[i];
}
}在这个例子中, 每次迭代都需要用到上一次迭代计算得到的 sum 值, 因此下一次迭代的计算操作必须等到上一次迭代的计算操作完成之后才能开始, 启动间隔最小取决于计算操作需要多少个周期.
在这个算法下, 强行让 II=1 也是可以的, 但加载完数据之后还是得要等待, 这会造成流水线停顿 (空泡), 是不推荐的做法.
要解决这种数据依赖的问题, 通常需要改变算法, 例如树形归约, 循环倾斜等技术, 拓展开讲会涉及到很多编译器优化技巧, 甚至是多面体模型, 这里就不展开介绍了, 可以参考另一篇文章 Advanced FPGA HLS: Polyhedral Compiling.
最后是一个使用 #pragma HLS pipeline 前后的综合报告对比, 综合使用的代码是
void vec_add(const int a[64], const int b[64], int c[64]) {
for (int i = 0; i < 64; i++) {
#pragma HLS pipeline II=1
// #pragma HLS pipeline off // 用于关闭流水线优化
c[i] = a[i] + b[i];
}
}将 size 参数改为编译时常量 64 是为了让编译器能在编译期间就计算出准确的总执行周期数.
未流水化, 循环的总周期数 128, 计算方式是 128(总周期数) = 64(迭代次数) * 2(每次迭代需要的周期数):
| Modules & Loops | Iteration Latency | Interval | Trip Count | Pipelined | Latency (cycles) | Latency (ns) | Slack | BRAM | DSP | FF | LUT | URAM |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
vec_add | - | 130 | - | no | 129 | 516.000 | 1.72 | - | - | 17 (~0%) | 97 (~0%) | - |
| VITIS_LOOP_2_1 | 2 | - | 64 | no | 128 | 512.000 | 2.92 | - | - | - | - | - |
流水线后, 循环的总周期数是 65, 计算方式是 65(总周期数) = (64(迭代次数) - 1) * 1(启动间隔) + 2(单次迭代的周期数):
| Modules & Loops | Iteration Latency | Interval | Trip Count | Pipelined | Latency (cycles) | Latency (ns) | Slack | BRAM | DSP | FF | LUT | URAM |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
vec_add | - | 65 | - | rewind | 66 | 264.000 | 1.29 | - | - | 16 (~0%) | 105 (~0%) | - |
| VITIS_LOOP_2_1 | 2 | 1 | 65 | yes | 65 | 260.000 | 2.92 | - | - | - | - | - |
对于流水线化后的结果, 总周期数的计算公式是: (总迭代次数 - 1) * 启动间隔 + 单次迭代的周期数. 第一项 (总迭代次数 - 1) * 启动间隔 实际上计算的是最后一次迭代的开始时间, 加上单次迭代的周期数自然就是总的完成时间了. 用符号表示是:
Total Cycles = (II - 1) * TC + IL
II = Initiation Interval (启动间隔)
TC = Trip Count (总迭代次数)
IL = Iteration Latency (单次迭代的周期数)#pragma HLS unroll
循环展开 (Loop Unrolling) 是另外一种常见的循环优化技术, 简单来讲是它将循环体内的操作复制多份, 允许编译器发现更多并行执行的机会. 例如下面的代码:
for (int i = 0; i < 4; i++) {
#pragma HLS unroll factor=2
c[i] = a[i] + b[i];
}会等价于
for (int i = 0; i < 4; i += 2) {
c[i] = a[i] + b[i];
c[i+1] = a[i+1] + b[i+1];
}编译器在编译的时候会发现这 2 份加法操作是互相独立的, 可以并行执行. 因此编译器会生成 2 份加法单元, 一次同时处理 2 个加法操作, 从而提高并行度和吞吐量. 下面是展开前后的调度时序图对比:
这种方法也能减少总的执行周期数. 在使用 #pragma HLS unroll 的时候, 需要注意以下几点:
- 循环本身是否能够展开? 对于有循环携带数据依赖的循环, 强行展开不一定会带来好处, 反而可能误导编译器, 因为数据依赖和并行化通常是冲突的.
- 展开因子 (
factor) 的选择: 显然factor越大, 并行度越高, 但资源占用也会根据factor成比例增加. 因此不要盲目追求高factor. - 如果省略
factor参数, 那么编译器会将循环完全展开 (Full Unroll). 这通常只适用于循环迭代次数非常小的情况. - 循环迭代次数是否是
factor的整数倍? 如果不是, 那么最后一次展开可能会超出循环边界. 例如下面的代码:
void vec_add(const int *a, const int *b, int *c, int size) {
for (int i = 0; i < size; i++) {
#pragma HLS unroll factor=2
c[i] = a[i] + b[i];
}
}编译器在编译的时候并不确定 size 能否被 2 整除, 即使你在使用这个模块的时候传入的 size 总是偶数, 编译器也不可能推断出这一点. 因此为了确保功能正确性, 会把代码变换为:
for (int i = 0; i < size; i += 2) {
c[i] = a[i] + b[i];
if (i + 1 >= size)
break;
c[i+1] = a[i+1] + b[i+1];
}显然这个 if 会引入额外的控制逻辑, 影响时序和资源使用. 为了向编译器传递更多信息, 告诉它我们能保证使用的时候 size 总是偶数, 编译器无需生成额外的控制逻辑, 有两种方式. 第一种方法是将 size 定义为一个编译时常量, 例如宏定义或者模板参数:
#define SIZE 1024
void vec_add(const int *a, const int *b, int *c) {
for (int i = 0; i < SIZE; i++) {
#pragma HLS unroll factor=2
c[i] = a[i] + b[i];
}
}但是这样做就丢失了灵活性, 这个模块编译后只能处理固定长度的向量. 第二种方法是加上 skip_exit_check 参数, 告诉编译器跳过边界检查:
void vec_add(const int *a, const int *b, int *c, int size) {
for (int i = 0; i < size; i++) {
#pragma HLS unroll factor=2 skip_exit_check
c[i] = a[i] + b[i];
}
}这样做的风险是如果传入的 size 不是偶数, 那么最后一次展开会访问越界的内存, 导致不可预期的后果. 因此只有在你保证传入的 size 一定满足要求的情况下才能使用这个参数.
最后是一个使用 #pragma HLS unroll 前后的综合报告对比, 综合使用的代码是
void vec_add(const int a[64], const int b[64], int c[64]) {
for (int i = 0; i < 64; i++) {
#pragma HLS pipeline off // 关闭编译器的自动流水线优化
#pragma HLS unroll factor=4
// #pragma HLS unroll off // 用于关闭循环展开优化
c[i] = a[i] + b[i];
}
}未展开的结果和 Pipeline 中的未流水化结果是一样的, 因此这里不再赘述. 展开后的结果如下:
| Modules & Loops | Iteration Latency | Interval | Trip Count | Pipelined | Latency (cycles) | Latency (ns) | Slack | BRAM | DSP | FF | LUT | URAM |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
vec_add | - | 50 | - | no | 49 | 196.000 | 1.72 | - | - | 35 (~0%) | 211 (~0%) | - |
| VITIS_LOOP_2_1 | 3 | - | 16 | no | 48 | 192.000 | 2.92 | - | - | - | - | - |
循环总周期数为 48, 计算方式是 48(总周期数) = 16(迭代次数) * 3(每次迭代需要的周期数). 这里迭代次数就是原始循环次数 64 除以展开因子 4 得到的结果 16. 显然总周期数减少了, 使用的资源也增加了.
这里单次迭代的周期数变成了 3, 是因为增加了更多的加法单元, 布线压力更大. 为了优化时序表现, 编译器增加了一些额外的寄存器来平衡路径延迟, 导致单次迭代的周期数增加了. 这也是 Unroll 可能带来的副作用之一, 太大的 Unroll 因子很容易导致时序无法收敛.
Unroll v.s. Pipeline
循环展开和流水线化都是为了追求高并行度和高吞吐量的技术. 它们之间有什么区别呢?
- 循环展开是通过空间上复制硬件操作单元来实现并行的, 例如增加
factor倍的加法单元来同时处理更多的加法操作. 而流水线化是通过时间上重叠不同操作的执行来实现并行的, 例如在前一次操作还没有完成的时候就开始下一次操作. - 两者都会增加硬件资源的使用量, 流水线化需要额外的控制逻辑和寄存器来存储中间状态, 循环展开需要增加更多的操作单元. 但在大多数情况下, 循环展开对资源使用的影响会更大一些.
- 循环展开通常用在循环次数已知且较少, 并且数据依赖明确的情况下. 流水线化通常用在循环次数较多, 并且希望最大化吞吐的情况下. 我个人的经验是, 循环展开用来构建基础的并行单元, 一个单元里面可能由好几块完全相同, 相互独立的功能模块组成; 而流水线化用来尽可能快速喂数据进这些并行单元, 以最大化利用率. 也就是说这两者是可以结合使用的, 互不冲突. 例如这个例子:
// 原始版本
void vec_add(const int *a, const int *b, int *c, int size) {
for (int i = 0; i < size; i++) {
c[i] = a[i] + b[i];
}
}
// 优化版本, 假设 size 是 2 的倍数
void vec_add(const int *a, const int *b, int *c, int size) {
for (int i = 0; i < size / 2; i++) {
#pragma HLS pipeline II=1
for (int j = 0; j < 2; j++) {
#pragma HLS unroll
c[2*i + j] = a[2*i + j] + b[2*i + j];
}
}
}在这里我通过对循环做了一个简单的改写, 分成两层嵌套的循环. 将内层循环展开, 构建一个 2 路并行的加法单元; 将外层循环流水线化, 尽可能快地喂数据进这个 2 路并行加法单元. 这样能兼顾资源使用和数据传输效率.
总之 Unroll 和 Pipeline 是可以结合使用的, 但并没有一个固定的公式可以套用, 以上只是我个人的一些经验之谈, 至于具体应该怎么结合, 参数应该怎么定, 还要考虑具体的算法结构.
最后是一个结合使用 Unroll 和 Pipeline 的综合报告对比, 综合使用的代码是:
void vec_add(const int a[64], const int b[64], int c[64]) {
for (int i = 0; i < 16; i++) {
#pragma HLS pipeline II=2
for (int j = 0; j < 4; j++) {
#pragma HLS unroll
c[4*i + j] = a[4*i + j] + b[4*i + j];
}
}
}| Modules & Loops | Iteration Latency | Interval | Trip Count | Pipelined | Latency (cycles) | Latency (ns) | Slack | BRAM | DSP | FF | LUT | URAM |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
vec_add | - | 32 | - | rewind | 35 | 140.000 | 1.27 | - | - | 97 (~0%) | 275 (~0%) | - |
| VITIS_LOOP_2_1 | 4 | 2 | 16 | yes | 34 | 136.000 | 2.92 | - | - | - | - | - |
一共只有 34 个周期. 尽管单次迭代的周期数变成了 4, 流水线的启动间隔变成了 2, 但总周期数仍然是到目前为止最少的. 这说明结合使用 Unroll 和 Pipeline 能带来更好的优化效果.
至于这里为什么启动间隔不能达到 1, 是资源冲突导致的, 更具体地说, 是内存端口数量限制导致的. 我们将在下一节立马知道这是怎么一回事, 又该如何解决.
#pragma HLS array_partition
数组分割 (Array Partitioning) 是一种常见的存储优化技术. 它通过将一个大数组分割成多个小数组, 以提高并行访问能力. 回到上面的例子, 在代码中我们没有向编译器说明任何端口的类型. 对于 a, b, c 这三个数组, 编译器会把数组默认综合成片上 RAM (LUTRAM/BRAM/URAM).
在数电课上或者 FPGA 设计课程上我们应该学过常见的 RAM 结构, 它们通常只有 1 个或者 2 个端口. 对于单端口 RAM, 在一个周期内只能进行一次读或者写操作. 双端口 RAM 则分两种, 一种是独立端口(True Dual Port), 可以在同一个周期内同时进行两次读或者写操作; 另一种是共享端口(Simple Dual Port), 只能在同一个周期内进行一次读和一次写操作. 但无论是哪一种, 最多都只能支持 2 次并发访问.
我们回到代码, 这里 unroll 默认完全展开, 也就是 factor=4. 这意味着编译器会尝试并行调度 4 次加法运算, 每次操作都需要独立的两次 Load 操作(a 和 b), 以及一次 Store 操作(c). 问题出在这里. a, b, c 三个数组每个周期最多只能支持 2 次并发访问, 但为了实现我们指定的并行度, 三个数组分别需要能支持 4 次并发访问, 而这在目前的配置下是不可能的. 因此编译器只能将每个数组的 4 次访问分到 2 个周期内完成. 既然加载操作需要两个周期, 参考 Pipeline 一节中的调度图, 不难发现启动间隔 (II) 最小只能是 2 了.
void vec_add(const int a[64], const int b[64], int c[64]) {
for (int i = 0; i < 16; i++) {
#pragma HLS pipeline II=2
for (int j = 0; j < 4; j++) {
#pragma HLS unroll
c[4*i + j] = a[4*i + j] + b[4*i + j];
}
}
}那我们需要通过拆分数组来提高并行访问能力. 例如下面的代码:
void vec_add(const int a[64], const int b[64], int c[64]) {
#pragma HLS array_partition variable=a dim=1 cyclic factor=2
#pragma HLS array_partition variable=b dim=1 cyclic factor=2
#pragma HLS array_partition variable=c dim=1 cyclic factor=2
for (int i = 0; i < 16; i++) {
#pragma HLS pipeline II=1
for (int j = 0; j < 4; j++) {
#pragma HLS unroll
c[4*i + j] = a[4*i + j] + b[4*i + j];
}
}
}由于我们已经知道, 默认情况下 Vitis 会将数组综合成双端口 RAM (如果需要的并发访问大于 1), 因此我们只需要将每个数据拆分成 2 个子数组, 每个子数组综合成一个双端口 RAM, 一共就是 4 个端口, 能够满足需求. 但是如何拆分实际上是一个问题, 主要有三种拆分方式: block , cyclic 和 complete.
-
complete是最好理解的, 直接将数组完全拆分成标量变量储存. 如果这样处理, 那在上面这个模块中, 你就会获得 64 * 3 = 192 个独立的模块端口. 显然这有点太多, 综合的时候几乎一定会导致时序问题, 只有对于非常小的数组才适用. -
block是将数组按块拆分, 例如将一个长度为 16 的数组, 以因子 8 拆分成 2 个子数组, 那第一个子数组存放索引 0-7 的元素, 第二个子数组存放索引 8-15 的元素. -
cyclic是将数组按循环方式拆分, 例如将一个长度为 16 的数组, 以因子 8 拆分成 2 个子数组, 那第一个子数组存放索引 0,2,4,6,8,10,12,14 的元素, 第二个子数组存放索引 1,3,5,7,9,11,13,15 的元素.
如何选择 block 还是 cyclic? 这完全取决于你希望达成的并行模式. 在向量加法的例子中不难发现, 我们要同时访问 4*i, 4*i+1, 4*i+2, 4*i+3 这 4 个连续的元素, 为了并行访问它们, 它们需要被分配到不同的子数组中. 这正好符合 cyclic 拆分的特点, 因此我们选择了 cyclic 拆分方式.
矩阵分块的另一个参数是 dim, 表示要拆分的维度. 对于一维数组, 只能是 dim=1. 对于高维数组, 例如二维数组 int A[2][4], dim=1 表示拆分行, dim=2 表示拆分列. 下图展示了沿着 dim=1 和 dim=2 以 factor=2 拆分二维数组的效果:
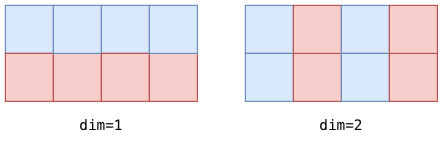
到这里你也许会问, 我都加了 #pragma HLS unroll 了, 为什么还需要 #pragma HLS array_partition 才能实现真正的并行呢? 实际上, 前者只是告诉编译器尝试进行并行调度, 而后者则是为并行调度提供必要的硬件支持. 只有在两者结合使用的情况下, 编译器才能真正实现高并行度的设计.
最后是一个加上 #pragma HLS array_partition 之后的综合报告对比, 综合使用的代码除了加上数组分割指令之外, 把流水线的启动间隔也改成了 1:
void vec_add(const int a[64], const int b[64], int c[64]) {
#pragma HLS array_partition variable=a dim=1 cyclic factor=2
#pragma HLS array_partition variable=b dim=1 cyclic factor=2
#pragma HLS array_partition variable=c dim=1 cyclic factor=2
for (int i = 0; i < 16; i++) {
#pragma HLS pipeline II=1
for (int j = 0; j < 4; j++) {
#pragma HLS unroll
c[4*i + j] = a[4*i + j] + b[4*i + j];
}
}
}| Modules & Loops | Iteration Latency | Interval | Trip Count | Pipelined | Latency (cycles) | Latency (ns) | Slack | BRAM | DSP | FF | LUT | URAM |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
vec_add | - | 17 | - | rewind | 18 | 72.000 | 1.27 | - | - | 16 (~0%) | 220 (~0%) | - |
| VITIS_LOOP_5_1 | 2 | 1 | 17 | yes | 17 | 68.000 | 2.92 | - | - | - | - | - |
可以看到总周期数变成了 17, 这是到现在为止周期数最少的设计了. 并且从资源利用上看到 BRAM 和 URAM 都是 0, 说明数组被综合成了 LUTRAM (LUT-based RAM), 整体设计的资源消耗非常合理且性能优秀.
到这里可以对比一下未 Pipeline 之前的最原始版本, 一步一步优化下来的中间版本, 以及最终版本的综合报告, 很显然在资源消耗没有显著增加的情况下, 每一步优化都给设计带来了更好的性能表现. 所以在 HLS 设计中, C++ 算法的编写只是第一步, 真正需要做出思考与权衡的是如何通过各种优化指令来引导编译器生成高效的硬件实现.
#pragma HLS dataflow
数据流 (Dataflow) 是一种更高级的并行化技术. 它允许设计被划分成多个独立的任务单元 (Task), 每个任务单元可以独立运行, 并通过 FIFO 通道进行数据传输. 这样不同的任务单元可以同时运行, 实现更高层次的并行化.
Dataflow 优化有一点类似于 Pipeline, 通俗一点讲, 它们的区别是 Pipeline 是在单个任务单元内实现操作的时间重叠, 而 Dataflow 则是在多个任务单元之间实现操作的时间重叠. 直观体现在代码上就是 Pipeline 是作用在循环上的, 而 Dataflow 是作用在函数或者代码块上的.
先理论分析一下, 假定有以下的伪代码:
void load(const int *ptr, hls::stream<int> &fifo, int size) {
for (int i = 0; i < size; i++) {
#pragma HLS pipeline II=1
fifo.write(ptr[i]);
}
}
void compute(hls::stream<int> &fifo_a, hls::stream<int> &fifo_b, hls::stream<int> &fifo_c, int size) {
for (int i = 0; i < size; i++) {
#pragma HLS pipeline II=1
// c[i] = a[i] + b[i];
int a = fifo_a.read();
int b = fifo_b.read();
fifo_c.write(a + b);
}
}
void store(hls::stream<int> &fifo, int *ptr, int size) {
for (int i = 0; i < size; i++) {
#pragma HLS pipeline II=1
ptr[i] = fifo.read();
}
}
void vec_add(const int *a, const int *b, int *c, int size) {
#pragma HLS interface m_axi port=a offset=slave bundle=gmem0
#pragma HLS interface m_axi port=b offset=slave bundle=gmem1
#pragma HLS interface m_axi port=c offset=slave bundle=gmem2
// other s_axilite interface pragmas
#pragma HLS dataflow
hls::stream<int> fifo_a;
hls::stream<int> fifo_b;
hls::stream<int> fifo_c;
load(a, fifo_a, size);
load(b, fifo_b, size);
compute(fifo_a, fifo_b, fifo_c, size);
store(fifo_c, c, size);
}不同于 Pipeline, Unroll 和 Array Partition 中的例子, 这里的 a, b, c 数组来自于外部内存, 而前者都作为 PL 端的一个中间模块, 也就是数据已经在片上了. 片上的数据交互几乎不用考虑带宽 (TB/s) 和延迟 (一两个周期到十几个不等) 的问题, 但外部内存的数据交互则完全不同. 例如发起一次内存读取请求在 DDR4 上可能需要几十个周期的延迟, 并且内存带宽常常是有限的(GB/s).
为了完成整个计算过程, 我们需要先将数据加载到片上, 然后进行计算, 最后将结果写回外部内存. 最直接的执行方式是, 计算模块等待加载模块将数据加载到片上, 然后开始计算, 计算完成之后再将结果写回外部内存, 然后加载下一批数据. 也就是完完全全的串行方式.
思考一下不难发现, 加载, 计算, 写回这三个任务彼此之间其实可以重叠进行. 在加载第一批数据的时候计算单元需要等待, 但一旦第一批数据加载完成, 计算单元开始工作的同时, 加载单元可以开始加载第二批数据; 当计算单元处理完第一批数据准备写回的时候, 加载单元也许已经完成了第二批数据的加载, 计算单元可以继续处理第二批数据, 同时写回单元开始将第一批结果写回外部内存. 调度图如下:
这看上去就是一种粗粒度的流水线. 不同执行单元的执行时间发生重叠, 从而提高整体的吞吐量. 在这种工作模式下, 数据像流水一样在不同的任务单元之间流动, 因此称之为数据流 (Dataflow).
但数据流优化并不那么简单. 不同模块之间的数据交互往往流量很大且数据依赖关系复杂, 而且模块的吞吐量差距也可能很大. 前者直接引出 Single-Producer-Single-Consumer (SPSC) 模式, 后者则引出背压 (Backpressure) 问题. 这两者都会影响数据流优化的效果, 甚至有的时候编译器会因为数据流违反 SPSC 模式而无法应用数据流优化.
首先讲讲背压问题. 假设有两个任务单元 A 和 B, A 的处理速度远快于 B. 那显然整体的进度会卡在 B 上, 而 A 会一直尝试给 B 喂远超 B 处理能力的数据. 于是数据就产生了“堆积”, 并且这些堆积的数据不能被丢弃 (因为它们都是有用的数据). 因此我们需要一个 FIFO 来容纳这些堆积的数据. FIFO 的特点是先进先出, 它能保证数据的顺序性, 作为一个中间缓冲, 但它的容量有限. 如果 A 一直以远超 B 的速度生产数据, 那么最终 FIFO 还是会被填满, 导致 A 必须暂停工作, 等待 B 处理完一些数据腾出一些 FIFO 空间之后才能继续工作. 最后形成的结果就是下游处理数据太慢导致上游只能断断续续地工作, 这种现象就叫做背压.
解决背压问题主要就是两种思路, 一种是简单粗暴的方法: 增加 FIFO 的深度. 这样能够容纳更多的数据堆积, 从而延缓背压的发生时间. 但 FIFO 通常会被综合成片上 RAM (LUTRAM/BRAM/URAM), 过度使用 LUTRAM 容易导致布线拥塞, 而 BRAM/URAM 的资源就相当有限了. 另一种方式是重新设计算法, 或者优化下游的计算模式, 尽可能平衡各个任务单元的吞吐量. 这通常是更有效的方式, 但也需要更多的设计工作量.
另一个是 SPSC 模式. 在数据流分析中除了 SPSC, 还有 MPMC, SPMC 等模式. MPMC 是 Multi-Producer-Multi-Consumer 的缩写, 意思是多个生产者和多个消费者同时访问同一个数据通道. 这种情况基本上不太可能出现, 因为会涉及到严重的同步问题, 而且性能也不好 (锁竞争), 硬件编译器也不会支持这种模式. SPMC 是 Single-Producer-Multi-Consumer 的缩写, 意思是单个生产者向多个消费者发送数据. 这涉及到数据的复用和广播 (Broadcast). 处理难度理论上比 MPMC 低一些, 但同样涉及到同步和数据一致性问题, 硬件编译器也不太支持这种模式. 在 Vitis 中, 官方直接说明了只支持 SPSC 模式这一种, 也就是单个生产者向单个消费者发送数据. 这就要求设计中每个 FIFO 通道只能在一处地方被写入, 并且只能在一处地方被读取. 如果违反了这个规则, 编译器就无法应用数据流优化.
在我们的 vec_add 例子中, 每个 FIFO 通道都严格遵守 SPSC 模式, 因此编译器能够成功应用数据流优化. 下面是加上 #pragma HLS dataflow 之后的综合报告对比, 综合使用的代码是:
void compute(hls::stream<int> &fifo_a, hls::stream<int> &fifo_b, hls::stream<int> &fifo_c) {
for (int i = 0; i < 64; i++) {
#pragma HLS pipeline II=1
// c[i] = a[i] + b[i];
int a = fifo_a.read();
int b = fifo_b.read();
fifo_c.write(a + b);
}
}
void store(hls::stream<int> &fifo, int *ptr) {
for (int i = 0; i < 64; i++) {
#pragma HLS pipeline II=1
ptr[i] = fifo.read();
}
}
void vec_add(const int *a, const int *b, int *c) {
#pragma HLS interface m_axi port=a offset=slave bundle=gmem0
#pragma HLS interface m_axi port=b offset=slave bundle=gmem1
#pragma HLS interface m_axi port=c offset=slave bundle=gmem2
#pragma HLS interface s_axilite port=a bundle=control
#pragma HLS interface s_axilite port=b bundle=control
#pragma HLS interface s_axilite port=c bundle=control
#pragma HLS interface s_axilite port=return bundle=control
#pragma HLS dataflow // enable/disable dataflow optimization
hls::stream<int> fifo_a;
#pragma HLS stream variable=fifo_a depth=32
hls::stream<int> fifo_b;
#pragma HLS stream variable=fifo_b depth=32
hls::stream<int> fifo_c;
#pragma HLS stream variable=fifo_c depth=32
load(a, fifo_a);
load(b, fifo_b);
compute(fifo_a, fifo_b, fifo_c);
store(fifo_c, c);
}未应用 Dataflow 优化的结果, 总周期数就等于各个模块周期数之和:
| Modules & Loops | Iteration Latency | Interval | Trip Count | Pipelined | Latency (cycles) | Latency (ns) | Slack | BRAM | DSP | FF | LUT | URAM |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
vec_add | - | 347 | - | no | 346 | 1.384e+03 | 0.00 | 64 (22%) | - | 8287 (3%) | 7549 (6%) | - |
vec_add_Pipeline_VITIS_LOOP_3_1 | - | - | - | yes | 67 | 268.000 | 0.00 | - | - | 1008 (~0%) | 126 (~0%) | - |
| VITIS_LOOP_3_1 | 3 | 1 | 64 | yes | 65 | 260.000 | 2.92 | - | - | - | - | - |
vec_add_Pipeline_VITIS_LOOP_3_11 | - | - | - | yes | 67 | 268.000 | 0.00 | - | - | 1008 (~0%) | 126 (~0%) | - |
| VITIS_LOOP_3_1 | 3 | 1 | 64 | yes | 65 | 260.000 | 2.92 | - | - | - | - | - |
vec_add_Pipeline_VITIS_LOOP_10_1 | - | - | - | yes | 67 | 268.000 | 0.44 | - | - | 44 (~0%) | 137 (~0%) | - |
| VITIS_LOOP_10_1 | 3 | 1 | 64 | yes | 65 | 260.000 | 2.92 | - | - | - | - | - |
vec_add_Pipeline_VITIS_LOOP_20_1 | - | - | - | yes | 67 | 268.000 | 0.00 | - | - | 526 (~0%) | 587 (~0%) | - |
| VITIS_LOOP_20_1 | 3 | 1 | 64 | yes | 65 | 260.000 | 2.92 | - | - | - | - | - |
使用了 Dataflow 优化的结果, 显然各个模块的执行时间发生了重叠.
| Modules & Loops | Iteration Latency | Interval | Trip Count | Pipelined | Latency (cycles) | Latency (ns) | Slack | BRAM | DSP | FF | LUT | URAM |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
vec_add | - | 64 | - | dataflow | 210 | 840.000 | 0.00 | 58 (20%) | - | 8906 (3%) | 6995 (5%) | - |
entry_proc | - | 0 | - | no | 0 | 0.000 | 1.46 | - | - | 3 (~0%) | 29 (~0%) | - |
load | - | 64 | - | rewind | 138 | 552.000 | 0.00 | - | - | 1349 (~0%) | 194 (~0%) | - |
| VITIS_LOOP_3_1 | 74 | 1 | 64 | yes | 136 | 544.000 | 2.92 | - | - | - | - | - |
load_1 | - | 64 | - | rewind | 138 | 552.000 | 0.00 | - | - | 1348 (~0%) | 185 (~0%) | - |
| VITIS_LOOP_3_1 | 74 | 1 | 64 | yes | 136 | 544.000 | 2.92 | - | - | - | - | - |
compute | - | 64 | - | rewind | 66 | 264.000 | 0.44 | - | - | 42 (~0%) | 140 (~0%) | - |
| VITIS_LOOP_10_1 | 2 | 1 | 64 | yes | 64 | 256.000 | 2.92 | - | - | - | - | - |
store | - | 64 | - | rewind | 136 | 544.000 | 0.00 | - | - | 854 (~0%) | 700 (~0%) | - |
| VITIS_LOOP_20_1 | 72 | 1 | 64 | yes | 134 | 536.000 | 2.92 | - | - | - | - | - |
这就是数据流优化带来的提升. 当然, 这里的例子比较简单, 实际上数据流优化更适合用于复杂的多阶段流水线设计中, 例如图像处理, 信号处理等领域.
关于数据流分析有一套比较系统的理论. 同时利用数据流优化去屏蔽外部内存访问延迟也涉及到比较复杂的设计技巧, 还需要对内存的访问模式和工作模型有一定的了解. 这里就不做赘述, 可以参考另一篇文章: Advanced FPGA HLS: Memory Access and Dataflow Optimization.
#pragma HLS bind_*
绑定 (Binding) 是一种资源优化技术. 它允许设计者指定特定的硬件资源来实现某些操作, 以优化性能或者资源使用. 比如对于浮点数乘除法, LUT 实现需要的时钟周期较多, 而且关键路径较长; DSP 实现则速度更快, 但资源相对有限. 通过绑定操作, 我们可以强制让编译器用指定的方式来实现某些操作 (编译器推断往往不够准确).
绑定操作主要有两种方式: 操作绑定 (Operation Binding) 和储存绑定 (Storage Binding). 操作绑定是将特定的计算操作绑定到特定的硬件资源上. 例如:
float A[M][K];
float B[K][N];
float C[M][N];
for (int i = 0; i < N; i++) {
for (int j = 0; j < M; j++) {
for (int k = 0; k < K; k++) {
#pragma HLS bind_op variable=C impl=maxdsp op=fadd latency=2
C[i][j] += A[i][k] * B[k][j];
}
}
}这里我们将对 C[i][j] 的归约加法操作绑定到了 DSP 上实现, 并且精确控制延迟为 2 个周期. 这样编译器在综合时就会优先考虑使用 DSP 来实现这个加法操作, 从而提高性能. 不过一味地追求低延迟有时候会导致综合失败, 即使 DSP 足够, 也可能导致时序无法满足.
bind_op 能绑定的操作类型主要是加减乘除, 对数指数, 平方根, 倒数. 实现的方式主要有 maxdsp, fulldsp, meddsp, fabric 等, 分别代表不同使用比例的 DSP 和 LUT 实现. 每种不同的实现方式和操作类型都有不同的延迟范围, 官网上有详细的表格说明, 可以参考: Vitis HLS Pragma and Directive Reference Guide.
储存绑定是将特定的数据存储绑定到特定的硬件资源上. 例如:
int cache[128][128];
#pragma HLS bind_storage variable=cache impl=bram type=ram_t2p这里我们将二维数组 cache 绑定到了 BRAM 上实现, 并且指定了 RAM 类型为 True Dual Port RAM. 这样编译器在综合时就会使用 BRAM 来实现这个数组, 并且使用双端口 RAM 结构, 从而提高并行访问能力. bind_storage 能绑定的存储类型主要有 bram, uram, lutram, 而 type 参数主要有 ram_1p, ram_2p, ram_t2p, ram_s2p, rom 等, 分别代表不同的存储结构和访问模式. 具体的参数说明也可以参考文档 Vitis HLS Pragma and Directive Reference Guide. 对于小位宽且规模不太大的数组, 用 LUTRAM 节省资源, 性能和时序表现也没差. 对于大位宽或者大规模的数组, 用 BRAM 或 URAM 通常能有更好的时序表现 (此时用 LUTRAM 容易导致布线拥塞).
一点建议
在 HLS 设计中查阅综合报告是非常重要的, 这关系到综合出来的时序, 资源符不符合你的需求, 更重要的是, 编译器有没有正确推断出你的设计意图. 一份完整的综合报告里面会有硬件端口映射, 循环调度信息, 有效 Pragma 列表 (如果 Pragma 无效或者无法达成会有警告). 综合的过程中不要忽略编译器给出的警告, 基本上所有的警告都表明了设计期望性能是无法达成的, 要么调整你的设计, 要么调整你的期望.
总结
本文介绍了 Vitis HLS 中几种常用的优化指令: #pragma HLS unroll, #pragma HLS pipeline, #pragma HLS array_partition, #pragma HLS dataflow, #pragma HLS bind. 除此之外还有很多其他的优化指令, 提到的指令也有很多的使用细节. 这篇文章仅仅作为入门介绍, 希望能帮助读者理解这些指令的基本概念和使用方法, 尝试建立起对 HLS 优化方法的基本认识. 实际使用时仍然应当参考官方文档, 并结合具体的设计需求进行优化.